Static corpus¶
The Q&A service lets you create a Q&A AI assistant that uses static data sources: company website pages, product manuals, guidelines, FAQ pages, articles and so on.
You can define the following types of static corpuses in the dialog script:
Web corpus: retrieve information from website pages and PDF files available online
Text corpus: use plain text as an information source
Web corpus¶
To define a web corpus for your Q&A AI assistant, use the corpus() function.
Note
The corpus() syntax differs between Alan AI SLU versions. Select the appropriate SLU version using the tabs below.
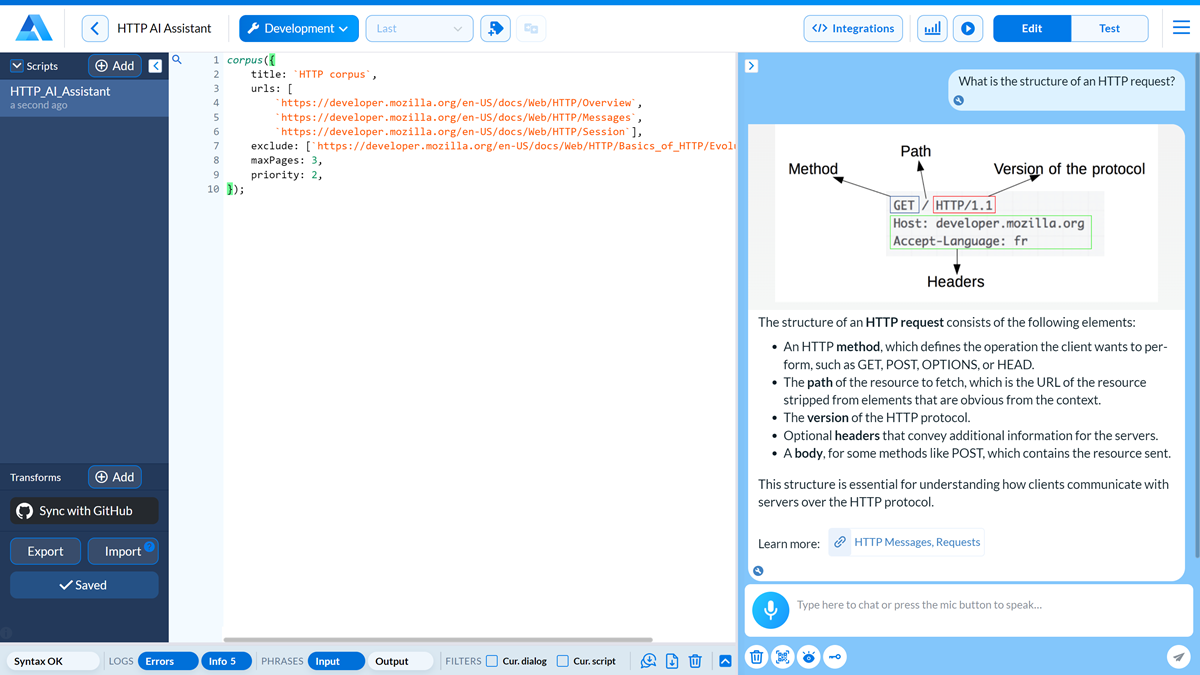
corpus({
title: `HTTP corpus`,
urls: [
`https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview`,
`https://developer.mozilla.org/en-US/docs/Web/HTTP/Messages`,
`https://developer.mozilla.org/en-US/docs/Web/HTTP/Session`],
exclude: [`https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/Evolution_of_HTTP`],
depth: 1,
maxPages: 5,
priority: 0,
});
Corpus parameters
Name |
Type |
Is Required |
Description |
|---|---|---|---|
|
string |
False |
Corpus title. |
|
string array |
True |
List of URLs from which information must be retrieved. You can define URLs of website folders and pages. |
|
string array |
False |
List of URLs to be excluded from indexing. You can define URLs of website folders and pages. |
|
integer |
False |
Crawl depth for web and PDF resources. The minimum value is 0 (crawling only the page content without linked resources). For details, see Data crawling. |
|
integer |
True |
Maximum number of pages and files to index. If not set, only 1 page with the defined URL will be indexed. |
|
integer |
False |
Priority level assigned to the corpus. Corpuses with higher priority are considered more relevant when user requests are processed. |
|
function |
False |
Transforms function used to process user queries. For details, see Dynamic corpus. |
|
function |
False |
Transforms function used to format the corpus output. For details, see Static corpus transforms. |
Note
Mind the following:
Make sure the websites and pages you define in the
corpus()function are not protected from crawling. The Q&A service cannot retrieve content from such resources.The indexing process may take some time. To check the progress and results, use the Alan AI Studio logs.
The maximum number of indexed pages depends on your pricing plan. For details, contact the Alan AI Sales Team.
Data crawling
The crawl depth defines how ‘far’ down the resource hierarchy the crawler must go to retrieve the content for the Q&A assistant. For example, if you set the crawl depth to 1, the crawler will access the page accessible at the start URL, extract all unique links to other pages in the same domain from this page and retrieve information from the start and linked pages.
Choose the crawl depth wisely. The deeper the level, the more likely users are to receive accurate answers to their questions. However, a deeper crawl depth may have an impact on the Q&A service’s performance.
corpus({
url: `https://developer.mozilla.org/en-US/docs/Web/HTTP/`,
depth: 1,
maxPages: 10,
});
Corpus parameters
Name |
Type |
Is Required |
Description |
|---|---|---|---|
|
string |
True |
Resource URLs from which information must be retrieved. You can define a URL of a website folder and page. |
|
integer |
False |
Crawl depth for web and PDF resources. The minimum value is 0 (crawling only the page content without linked resources). For details, see Data crawling. |
|
integer |
True |
Maximum number of pages and files to index. If not set, only 1 page with the defined URL will be indexed. |
Data crawling
The crawl depth defines how ‘far’ down the resource hierarchy the crawler must go to retrieve the content for the Q&A assistant. For example, if you set the crawl depth to 1, the crawler will access the page accessible at the start URL, extract all unique links to other pages in the same domain from this page and retrieve information from the start and linked pages.
Choose the crawl depth wisely. The deeper the level, the more likely users are to receive accurate answers to their questions. However, a deeper crawl depth may have an impact on the Q&A service’s performance.
Note
Mind the following:
Make sure the websites and pages you define in the
corpus()function are not protected from crawling. The Q&A service cannot retrieve the content from such resources.The indexing process may take some time. To check the progress and results, use the Alan AI Studio logs.
The maximum number of indexed pages depends on your pricing plan. For details, contact the Alan AI Sales Team.
Text corpus¶
To define a text corpus for the Q&A AI assistant, add plain text strings to the corpus() function:
corpus(`
Hi, I am your HTTP AI assistant.
I'm here to offer insights into the HTTP protocol.
I can answer any questions regarding HTTP requests and responses, status codes, sessions and more.
Need assistance unraveling the complexities of HTTP protocol? I'm at your service with clear explanations.
`)